
In this article you'll get to know about some of the best text processing and filtering commands that every Linux person should know about. If you are starting your career in the Linux world or trying to get a new job in this field, then you must be familiar with these commands and tools.
Introduction
Text processing and filtering commands are used to manipulate or modify the text data. These are powerful tools made to handle text-based information efficiently. I'll be using Linux Mint 21.2 GUI version for demonstrations. These commands are the same and available in all distributions so you can pick any Linux distribution.
These tools are mainly used on server or CLI versions of Linux because there is no Graphical User Interface present to interact with the Operating System. Below are some of the best and most used text processing commands.
To do it more practically, use the below command to create a new file with some text in it:echo -e "Two legends rise, in dark and gleam,\nTheir quests for justice, a timeless theme.\nOne cloaked in night, the other in steel,\nTheir valorous spirits, a heroic seal.\n\nIn worlds apart, their stories told,\nYet both wear masks, a tale unfolds.\nBatman and Ironman, in their own way,\nShield the world, where heroes sway." > heroes.txt
Here I'm using echo command to write some text into heroes.txt named file. We'll use this file to perform various operations throughout the process.
grep command
grep command is used to search in text. Search can be based on a specific string or pattern. grep command comes pretty handy when it comes to searching some text in a file or even in the output text of some other command.
Now Let's say we want to search word bat in this file, we'll use grep command like this:
grep -i "bat" heroes.txt
$
grep -io "bat" heroes.txt
This command will look for word bat in heroes.txt file. Every line that contains the specified word will be printed as output in the terminal.
 As you can see in the above image, there is only one line that contains the specified word.
As you can see in the above image, there is only one line that contains the specified word.
- Option i is used to ignore the lettercase while searching.
- Option o in the second command is used to print only the specified string, if found, instead of the whole word or line.
Now here comes the real thing. Let's say you have a file with 1000 lines of text and you want to find and count the appearance of a specific keyword. This is where grep is so much fun. After filtering the word, We can further process the output produced by grep command.
Use the below command to count the appearance of specified word:grep -io "in" heroes.txt|wc -l
In the above command, we used wc command for further processing the text output produced by grep command. This wc -l will count the output lines.

As shown in the image above, there are 5 appearances of in word inside the heroes.txt file. This way we can use grep for filtering the text and then further process that output using other commands. Use grep --help to know more about grep command and options that can be used with it.
awk command
awk is text processing language used for recognizing patterns and processing text. It extracts and manipulates text from files along with formatting and calculations. Its primary function is to break down lines into fields and then process those fields further using various operations.
It can arrange and print text output based on a specified delimiter. Let's say we want to print the first field of every line from our file, awk command can perform this operation like this:
awk '{print$1}' heroes.txt
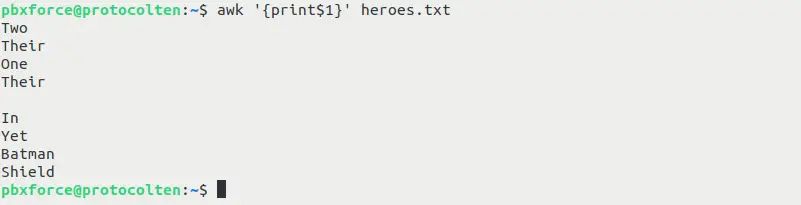
As you can see in the image above, awk prints the first field of every line. Fields are separated by a delimiter. awk uses whitespace as default delimiter to seperate fields.
awk '{print$1,$3}' heroes.txt
The Above command will print the first and third fields separated by whitespace delimiter. It will produce the output as shown in below image:
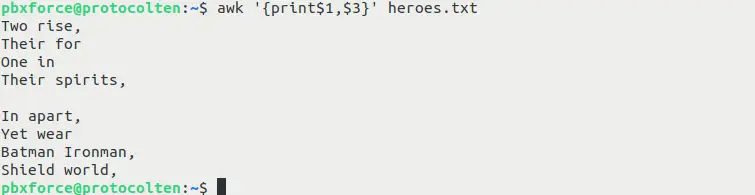
If you want to use another delimiter instead of default whitespace, use the following option with awk command to achieve this:
awk -F',' '{print$1}' heroes.txt
Here i used -F option to specify , as delimiter. Now the fields will be seperated by , instead of whitespace. This command will print the first field based on the specified delimiter.
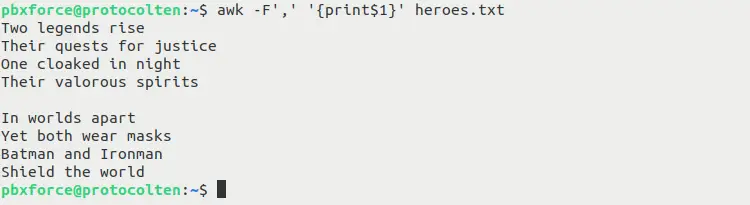
Using a custom delimiter can be very useful when the text content of a file is formatted with other delimiters instead of whitespace.
You can combine awk and grep command together for further text processing.
grep -i 'bat' heroes.txt|awk '{print$3}'
This command will utilize both grep and awk tools together. First, grep will search and filter out the bat keyword from the specified file, and then awk command will print the first field from output produced by grep command using the default delimiter.

Using grep and awk together is a great combination to process the output text. You can execute awk --help or man awk commands to know more about this tool.
cut command
cut command is used for extracting a particular section or field from a file or output text of other commands. It also worked on the basis of delimiter. The main use cases of this command are to further process the output text or print the output from a file that contains structured data formatted by delimiter.
cut command comes in handy when the goal is to produce output more controlled than usual. Use the below command:
cut -c1-3 heroes.txt
In this command, I'm specifying to print only 1 to 3 characters of each line. The following output will be produced:

As you can see, the command only printed the first three characters of each line from the file, as specified in the command. Just remember that whitespace is also counted as a character when working with the cut command.
Now we know that the cut command also works with a delimiter, so let's try it. Unlike awk, there is no default delimiter in cut command. You have to specify the delimiter manually if you want to process the text on delimiter basis. Use command:
cut -d, -f2 heroes.txt
In this command, option -d is used to specify , as prefered delimiter. Option -f2 specifies the field that we want. This command will produce the below output:
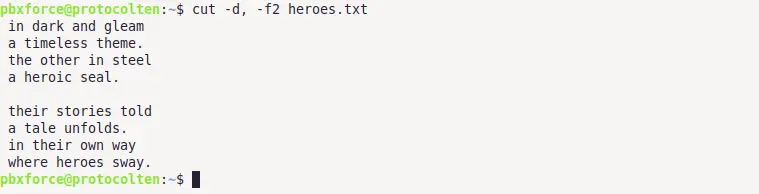
As specified in the command, lines are seperated by , and second field is printed as output. We can further process the output text by using grep or awk command if required.
Using grep, awk, and cut commands together are very practical and more common than you think. Linux experts often use combinations of various text-processing commands to produce the desired output. Use the below command:
awk '{print$1,$3}' heroes.txt|grep -i "batman"|cut -d, -f1
Now this command is composed from awk, grep and cut commands. The purpose of this command is to utilize these tools in a way to produce the output that otherwise is not possible without manually opening and altering the file.
 Let's break down what each command means:
Let's break down what each command means:
- awk '{print$1,$3}' heroes.txt command will print first and third field seperated by whitespace (default delimiter in awk) as output.
- grep -i "batman" command will further process the output produced by awk command and output the line that contains keyword bat.
- cut -d, -f1 command will further process the output produced by grep command. It will separate the fields by , delimiter and print the first field as final output.
This way you can use multiple text processing commands together to serve the purpose. Any output produced by any other Linux command can be further processed by these commands.
sort command
sort command is used to sort the lines of a file or text output in alphabetical or numerical order. The purpose of this command is to arrange the data in a specific order. Use the below command:
sort heroes.txt

As you can see in the image above, sort command arranged the lines in aplhabetical order. Just remember that an empty will always appear first in alphabetical order.
Just like other text processing commands, you can also use sort command to further process the output produced by other commands. Use below command to use it with grep command:
grep -i 'in' heroes.txt|sort

As shown in the image above, output produced by grep command is further processed using sort command to arrange the lines in aplhabetical order. Use sort --help to know about the options that can be used with this command.
uniq command
As the name states, uniq command is used to filter out the duplicate lines from the file or output text of other commands. This command is most useful when you have duplicate lines multiple times in the file or data stream and you want to filter out those duplicate lines while getting information about what lines were duplicated. Use command:
echo -e "batman\nironman\nbatman" | sort | uniq

As you can see in the above image, executed commands contain two times word batman but the output contains only once because duplicate entry has been deleted by the uniq command.
If you want to know what duplicate lines are removed from the output, use the below command with -c option. Run the below command:
echo -e "batman\nironman\nbatman" | sort | uniq -c

Here you can see that word batman was appeared in 2 lines. So the duplicate line has been removed from the output but in the meantime, also let the user know what word was duplicated. Use uniq --help to know more about options that can be used with this command.
tr command
tr stands for translate. This command is used to replace or delete characters from the input text file or standard text input. Use the below commands for better understanding:
cat heroes.txt|tr 'a' 'e'
Here I'm printing the content of our text file using cat command and then pass the printed text as standard input to tr command where It'll replace character a with e and produce the standard output as shown in the image above.
tr can also be used to remove the character. Use the below command:
cat heroes.txt|tr -d 'a'

In the above command, I'm using tr to remove a character from the standard input. As you might have noticed in the image above, character a has been removed from everywhere. Use tr --help to explore more options about this command.





