
AWS S3 is an object-level storage service that can be utilized in various ways, including data backup. From JSON files to images, a S3 bucket can contain anything. But sometimes having too many objects can cause some issues, especially if these objects are not very relevant to you.
In this article, I'll be sharing a Python script, as a solution for the same kind of problem. This Python script will grab all your S3 bucket images and create a single PDF file. Easy to use and it could be very helpful in some cases. This script is written and tested on Ubuntu 20.04 LTS using Python3.8
Python script for image to PDF
I've writen a Python script that will grab all the images from the appropriate S3 bucket folder, create a new PDF file in another folder, and later on remove the images from S3 bucket (optional).
This script is written and tested on Debian based Linux distribution but It'll work on any Linux distribution. Before executing this Python script, you need to configure your system with AWS Credentials in order to access AWS resources locally using Python code.
Creating access key and configuring AWS locally
Creating Access key: To interact with your AWS account from local system or using Python code, you need Access key of your AWS account. If you don't have one already, follow the below steps to create new access key:
- Login to your AWS management console.
- On top-right side of screen, click on your username and select Security credentials from the list.
- Scroll down to the Access key sections and click on Create access key to generate new key.
- From use cases options, select Local code and click on "Next" button. In Description tag value, you can write what this key is about. You leave it blank because It's optional. Click on "Create access key" to generate new key.
Now that you have the Access key of your AWS account, either download the key file or note down the Access key ID and Secret access key.
Configuring AWS on local system: First you need to install awscli package to access your AWS resources and services locally from terminal. Use the below command:
sudo apt install awscli
After installing the package, run aws configure command to initialize the AWS
configuraiton process.
- AWS Access Key ID [None]: Enter the ID of your newly created AWS Access key.
- AWS Secret Access Key [None]: Enter the Secret key of your newly created AWS Access key.
- Default region name [None]: Enter the Default region name. If not specified explicitly, this region will act as the default region while executing any command from terminal. Enter region name where your bucket is created. My bucket is created in Oregon, so us-west-2 should be my Default region.
Run aws configure command again to check if you want to do
any changes in the configuration. To check if AWS is configured successfully, use aws s3 ls command to list all AWS S3 buckets:

Even though the above screenshot is not from the local terminal, if your AWS CLI configuration is correct, the output of above command should look like that in the images.
Executing python script
Now that the AWS Configuration on local system is completed. You can execute the Python command and It'll automatically utilize the AWS Access key to access services and resources in our case particularly S3.
Before executing the script, create new virtual environment and install pip packages required by the script.
- To create a new virtual environment named env, use
python3 -m venv envcommand in the terminal. - Run
source env/bin/activateto activate this virtual environment. - To install all the required Python packages, use
pip install -r requirements.txtcommand. Make sure to run this command inside the same directory as requirements.txt or you can provide the absolute path of the requirements.txt file.
python3 s3_images_to_pdf.py
- Enter S3 bucket name (For ex: my-bucket): In the first input prompt, enter the name of your bucket.
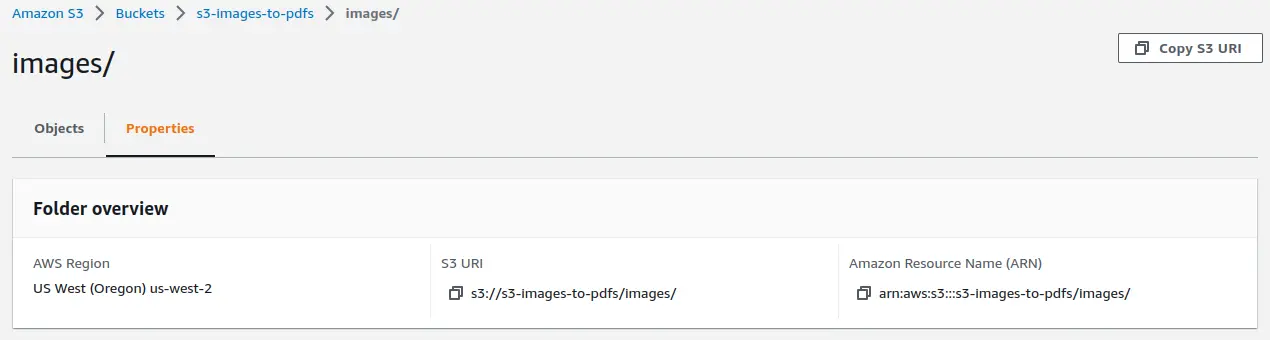
- Enter S3 URI of images folder
(For ex: s3://my-bucket/images/): In the second input prompt, enter the S3 URI
(Unique resource identifier) of your folder that resides inside the bucket and contains
all the images. Click on the folder name and then select Propeties to get the S3 URI of that
folder.
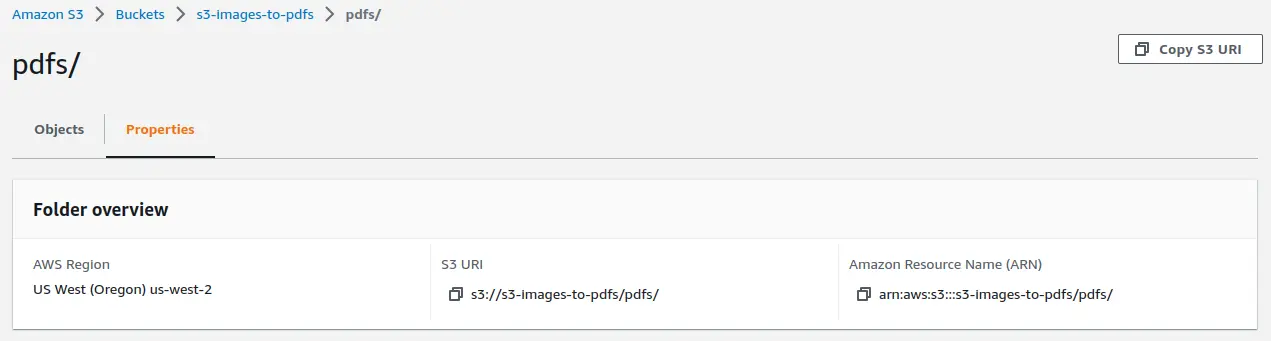
- Enter S3 URI of folder where
to save PDF files (For ex: s3://my-bucket/pdfs/): In third input prompt,
enter the S3 URI of your folder that resides inside the bucket and will contain output
PDF files. Click on the folder name and then select Propeties to get the S3 URI of that
folder.

Script is usually pretty fast but the actual execution time depends on the number of images in the folder. After the process is completed, go to AWS S3 console and check your pdfs folder in the bucket, there will be a new PDF file that contains all your images.
Remove images from bucket folder after process: The Default behavior of script is to preserve images as it is. But you can pass an optional argument to remove the images from the bucket after converting them into PDF. Run the below command:
python3 s3_images_to_pdf.py --delete-images
Using this optional argument while executing the script, you can clean up your images folder after converting all the images into a PDF file.
Conclusion
This script can be useful for various purposes. Possibilities are endless as you can customize the script as per need. By default, images are appended into pdf file in 500x500 pixels but this behavior can be changed easily. There is one other file lambda_function.py in this repository, which was written to demonstrate how AWS Lambda works with S3 trigger. Checkout this article Lambda trigger with S3 to know about the script.





